Vortrainierte Keypoint-Detection-Modelle sind leistungsstark, aber sie wurden fast ausschließlich für die Erkennung menschlicher Körperhaltungen trainiert. Wer Interessenpunkte an Objekten, Maschinen, Fahrzeugen oder domänenspezifischen Motiven erkennen möchte, muss ein eigenes Modell trainieren. Diese Anleitung führt durch den gesamten Prozess: von der Datenstrategie und Annotation über die Framework-Auswahl bis zur Inferenzkonfiguration, inklusive funktionierendem PyTorch-Code.
Was ist Keypoint Detection?
Keypoint-Detection-Modelle identifizieren spezifische Punkte von Interesse in einem Bild: Gelenke, Ecken, Landmarken oder beliebige semantisch bedeutsame Positionen, die Sie definieren. Während Bildklassifikation, Objekterkennung und Segmentierung die gängigsten Computer-Vision-Anwendungen von Künstlicher Intelligenz und Machine Learning sind, ist Keypoint Detection die richtige Wahl, wenn Sie Pose, Winkel und Dimensionen von Objekten schätzen müssen, statt sie lediglich zu klassifizieren oder einzurahmen.
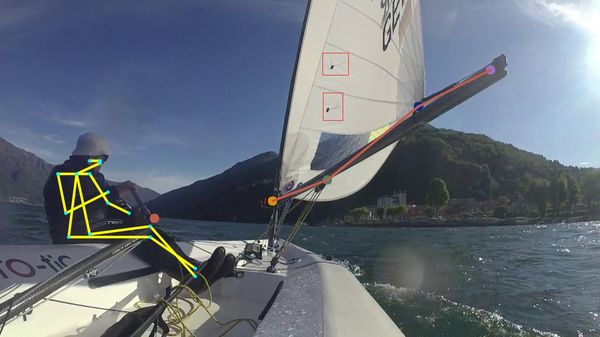
Neuronale Netzwerke, insbesondere R-CNN-Architekturen (Region-based Convolutional Networks), sind der aktuelle Best Practice für Keypoint-Detection-Genauigkeit. Wir haben diesen Ansatz selbst eingesetzt, um die Position von Segelbootkomponenten in Echtzeit zu erkennen und zu schätzen.
Anwendungsfälle und Einsatzbereiche
Keypoint-Detection-Modelle sind in einer Vielzahl von Branchen wertvoll:
- Sports Analytics: Tracking von Athleten- und Ausrüstungspose, Erkennung von Technikfehlern
- Gesundheitswesen: Medizinische Bildgebung, Rehabilitationsmonitoring, chirurgische Assistenz
- Industrieautomation: Fehlererkennung, Montageverifikation, Roboterführung
- E-Commerce: Körperposenerkennung für virtuelle Anproben
- Autonome Systeme: Objektorientierungsschätzung für Navigation und Manipulation
Kosten, Zeit und Aufwand für das Training eines Keypoint-Detection-Modells
Bevor Sie ein Keypoint-Detection-Modell in Auftrag geben, ist es hilfreich, den typischen Aufwand und die Kosten zu verstehen. Die Zahlen variieren erheblich je nach Anwendungsfall. Die folgende Tabelle gibt einen realistischen Überblick für die Entwicklung eines ersten funktionierenden Prototyps, ausreichend um die Machbarkeit zu validieren und die wichtigsten Herausforderungen zu identifizieren, bevor in ein produktionsreifes System investiert wird.
| Aktivität | Aufgabe | Geschätzter Aufwand |
|---|---|---|
| Datenbeschaffung | 50–100 repräsentative Bilder aufnehmen | 1–2 Tage (verteilt, um Variation abzudecken) |
| Annotation/Labeling | Bounding Boxes und Keypoints pro Bild markieren | 1–2 Stunden für 50–100 Bilder |
| Modelltraining | Keypoint Detector konfigurieren und trainieren (Standardansatz) | ca. 1 Tag mit einem Standard-Framework |
| Evaluation & Iteration | Ergebnisse prüfen, Konfiguration anpassen, neu trainieren | 0,5–2 Tage je nach Qualitätsanforderungen |
Diese Schätzung ist bewusst konservativ. Das Ziel eines Prototyps ist es, schnell ein funktionierendes Modell zu erhalten und domänenspezifische Herausforderungen frühzeitig zu identifizieren. Produktionsreife Modelle erfordern mehr Daten, rigorosere Annotation und eine vollständige MLOps-Deployment-Pipeline. Für eine genauere Einschätzung Ihres konkreten Anwendungsfalls sprechen Sie uns gerne an.
Datenstrategie für das Training eines Keypoint-Detection-Modells
Eigene Datenbeschaffung
Der Standardansatz ist die gezielte Aufnahme von Bildern für Ihren Anwendungsfall. Sowohl Bilder als auch Annotationen werden für das Training benötigt.
Beginnen Sie mit dem Fotografieren des Objekts mit den Keypoints unter variierenden Bedingungen: verschiedene Winkel, Umgebungen und Lichtverhältnisse. Variation ist entscheidend: Ein Modell, das nur auf gut ausgeleuchteten Studioaufnahmen trainiert wurde, wird im Einsatz schlechter abschneiden. Für einen ersten Prototyp sind 50–100 Bilder ein praktischer Ausgangspunkt. Skalieren Sie die Datenmenge schrittweise, wenn Annotations- und Architekturprobleme gelöst sind.
Der nächste Schritt ist das Labeling der Daten. Sie müssen sowohl die Bounding Box des Objekts als auch die Pixelkoordinaten jedes Keypoints markieren. Das ist zeitaufwändige, repetitive Arbeit. Für einen Prototyp lohnt es sich oft, dies zunächst intern zu tun, um den Annotationsprozess und Sonderfälle vollständig zu verstehen, bevor die Arbeit im großen Maßstab ausgelagert wird. Präzise, konsistente Labels sind entscheidend, da Label-Rauschen eine der häufigsten Ursachen für schwache Modellperformance ist.
Synthetische Bilder verwenden
Wenn die Datenbeschaffung in der realen Welt unpraktisch ist (aufgrund von Kosten, Sicherheitseinschränkungen oder Seltenheit des Szenarios) sind synthetische Bilder eine leistungsstarke Alternative. Mit Python und einer 3D-Rendering-Engine wie Blender können fotorealistische Bilder von Objekten in beliebigen Posen generiert werden, wobei die Keypoint-Koordinaten automatisch aus den Rendering-Parametern bekannt sind.
Der entscheidende Vorteil: Keine manuelle Annotation erforderlich, und der Datensatz kann nahezu sofort auf Tausende von Bildern skaliert werden. Data Augmentation (Helligkeit, Weichzeichner, Verdeckung) fügt weitere Variation hinzu und verbessert die Generalisierung auf reale Bedingungen.
Öffentliche Datensätze nutzen
Es lohnt sich immer zu prüfen, ob ein geeigneter öffentlicher Datensatz bereits existiert. Der COCO-Datensatz ist der verbreitetste Benchmark für Keypoint Detection, aber es gibt auch domänenspezifische Datensätze für medizinische Bildgebung, industrielle Inspektion und Sportanwendungen. Die Nutzung eines öffentlichen Datensatzes, auch nur teilweise, kann den Annotationsaufwand erheblich reduzieren und einen stärkeren Ausgangspunkt für Transfer Learning bieten.
Annotationstools für Keypoint Detection
Sobald Sie Ihre Bilder haben, benötigen Sie ein Annotationstool mit Keypoint-Unterstützung. Eine populäre Open-Source-Wahl ist COCO Annotator, der Bounding Boxes und Keypoints nativ unterstützt und im COCO-JSON-Format exportiert, das die meisten Frameworks direkt verarbeiten können. Für Teams mit höheren Anforderungen bieten Labelbox und Scale AI verwaltete Annotations-Workflows.
Frameworks für das Training eines Keypoint Detectors
Zwei Frameworks dominieren die praktische Keypoint-Detection-Arbeit:
Detectron2
Detectron2 ist Facebooks KI-Bibliothek für Objekterkennung, Segmentierung und Keypoint Detection. Der Detectron2 Model Zoo enthält vortrainierte Keypoint-R-CNN-Gewichte auf dem COCO-Personen-Datensatz. Detectron2 ist eine starke Wahl, wenn Sie eine bewährte, konfigurierbare Pipeline mit minimalem eigenem Code wünschen.
PyTorch
PyTorch bietet eine KeypointRCNN-Implementierung in torchvision, die auf benutzerdefinierten Datensätzen feinabgestimmt werden kann. Es bietet mehr Flexibilität als Detectron2 für benutzerdefinierte Architekturen und lässt sich leichter in breitere Python-ML-Pipelines integrieren.
Schritt für Schritt: Custom Keypoint Detector mit PyTorch trainieren
Daten vorbereiten
Das Keypoint-Detection-Modell benötigt Bilder und zugehörige Annotationen. Annotationen müssen die Bounding Box jeder Objektinstanz und die Pixelkoordinaten jedes Keypoints enthalten. Bei Videos müssen zunächst die relevanten Frames extrahiert werden.
Data Augmentation wird empfohlen: Zufällige Spiegelungen, Helligkeitsänderungen und Skalierungsvariationen fügen Variation hinzu, die dem Modell hilft zu generalisieren. Dies ist besonders wichtig bei kleinen Datensätzen.
PyTorch Dataset und DataLoader verwenden
PyTorchs Dataset-Klasse bietet eine saubere Abstraktion zum Laden von Bildern und Annotationen. Die folgende Implementierung lädt Bilder von der Festplatte, konvertiert sie in Tensoren und gibt Bounding Boxes, Keypoint-Koordinaten und Klassen-Labels in dem von KeypointRCNN erwarteten Format zurück:
class KeypointsDataset(Dataset):
def __init__(self, img_dir: Path, annotations_dir: Optional[Path] = None):
self.img_dir = img_dir
self.annotations_dir = annotations_dir
self.images = sorted(list(self.img_dir.iterdir()))
self.annotations = None
if annotations_dir:
self.annotations = []
for image in self.images:
self.annotations.append(self.annotations_dir / f"{image.stem}.json")
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = Image.open(self.images[idx])
image_tensor = ToTensor()(image)
target = {}
if self.annotations:
with open(self.annotations[idx], "r") as f:
annotations = json.load(f)
target = {
"boxes": torch.Tensor([a["box"] for a in annotations]),
"keypoints": torch.Tensor([a["keypoints"] for a in annotations]),
"labels": torch.Tensor([1 for _ in annotations]).type(torch.int64),
}
return image_tensor, targetKombinieren Sie dies mit PyTorchs Standard-DataLoader. Sie benötigen wahrscheinlich eine benutzerdefinierte collate_fn, um Annotationslisten variabler Länge korrekt zu batchen.
KeypointRCNN-Modell konfigurieren
Das KeypointRCNN-Modell bietet mehrere wichtige Konfigurationsparameter:
- Backbone-Architektur: bestimmt die Feature-Extraktion. ResNet-50 ist der Standard und der einzige Backbone, der derzeit mit vortrainierten COCO-Gewichten geliefert wird. Komplexere Backbones verbessern die Genauigkeit auf Kosten des Inferenz-Durchsatzes.
- Anzahl der Keypoints: muss mit der Anzahl der in Ihren Annotationen definierten Interessenpunkte übereinstimmen.
- Anzahl der Klassen: immer auf N + 1 setzen, um die Hintergrundklasse zu berücksichtigen. Für einen Einzelklassen-Detektor ist dies 2.
- Maximale Erkennungen pro Bild: begrenzt Rauschen zur Inferenzzeit, wenn die erwartete Objektdichte in Ihrer Szene bekannt ist.
Modell trainieren
Teilen Sie Ihre Daten in Trainings- und Validierungssets auf. Eine GPU mit CUDA-Unterstützung reduziert die Trainingszeit erheblich. Überwachen Sie während des Trainings sowohl den Trainings- als auch den Validierungsverlust. Wenn der Keypoint-Verlust bei null bleibt, ist die häufigste Ursache eine falsch konfigurierte Klassenanzahl (überprüfen Sie, ob Klassen-Labels keine 0 enthalten, da diese für den Hintergrund reserviert ist) oder Annotationen, die nicht mit der konfigurierten Keypoint-Anzahl übereinstimmen.
PyTorchs torch.save / torch.load ermöglicht das Checkpointing von Modellen in regelmäßigen Abständen, was manuelle Zwischenevaluationen und eine saubere Wiederaufnahme des Trainings ab jeder Epoche erlaubt.
Inferenz-Pipeline konfigurieren
Nach dem Training haben zwei Inferenzparameter den größten Einfluss auf die Ausgabequalität:
box_score_thresh: der Erkennungs-Konfidenz-Schwellenwert. Erhöhen Sie diesen, wenn zu viele fehlerhafte Erkennungen auftreten; verringern Sie ihn, wenn das Modell gültige Objekte übersieht.box_nms_thresh: der Non-Maximum-Suppression-Schwellenwert, der die Überlappung zwischen vorhergesagten Boxen kontrolliert. Reduzieren Sie diesen, wenn eine einzelne Objektinstanz mehrfach zurückgegeben wird.
Sobald Ihr Modell gut performt, erwägen Sie den Export nach ONNX für laufzeitunabhängiges Deployment oder die Verwendung von TorchScript für die Integration in Python-Produktionsdienste ohne vollständige PyTorch-Installation.
Wie adagger helfen kann
Das Training eines Keypoint-Detection-Modells auf einem benutzerdefinierten Datensatz erfordert weit mehr als das Ausführen eines Trainingsskripts. Datenstrategie, Annotationsqualität, Architekturauswahl und Produktions-Deployment erfordern alle erfahrenes Urteilsvermögen, um effizient zu einem guten Ergebnis zu kommen.
Bei adagger haben wir Keypoint-Detection-Systeme für Sports Analytics, industrielle Inspektion und autonome Anwendungen entwickelt. Wir können Ihnen helfen, die Datenbeschaffungs-Pipeline zu entwerfen, Annotationen im großen Maßstab zu verwalten, die richtige Architektur für Ihre Genauigkeits- und Latenzanforderungen auszuwählen und das Modell als Produktions-API zu deployen, containerisiert, überwacht und bereit für die Integration in Ihr Produkt.
Nehmen Sie Kontakt mit uns auf, um Ihr Keypoint-Detection-Projekt zu besprechen. Wir beraten Sie gerne zu Machbarkeit, Umfang und dem schnellsten Weg zu einem funktionierenden Prototyp.
Fazit
Keypoint Detection ist eine leistungsstarke Computer-Vision-Fähigkeit, die weit über die Erkennung menschlicher Körperhaltungen hinausgeht. Mit der richtigen Datenstrategie, einem sorgfältigen Annotationsprozess und korrekter Framework-Konfiguration ist es möglich, aus einem überschaubaren Datensatz ein produktionsreifes Modell zu trainieren. PyTorch und Detectron2 bieten ausgereifte, flexible Implementierungen für eine Vielzahl von domänenspezifischen Anwendungsfällen. Die Hauptinvestition liegt in Datenqualität und Annotationsdisziplin, nicht in der Modellierungskomplexität.